Speechmatics provides multilingual speech-to-text, text-to-speech, and voice AI technology. It turns voice into actionable insights through transcription, translation, and summarization for workflows in media, contact centers, healthcare, education, legal, finance, and AI infrastructure. Core offerings include real-time and batch speech-to-text with accuracy across 55+ languages, speaker diarization, and speech intelligence features like summarization, sentiment analysis, and topic detection. Deployments cover cloud API, on-premises, on-device, and edge/hybrid options. Text-to-speech generates natural synthetic voices. Developer tools include REST and WebSocket APIs plus SDKs for Python and Node.js.
Super accuracy in the medical domain for US healthcare documentation
Low word error rates in multilingual and accented English benchmarks
High performer rating in speech recognition
Improved accuracy across major languages and new features like language identification
Text-to-speech limited to preview with four English voices only
No control over voice speed, pitch, or emphasis in text-to-speech
Usage-based pricing applies after free tier limits
30 Days
Yes
Proprietary
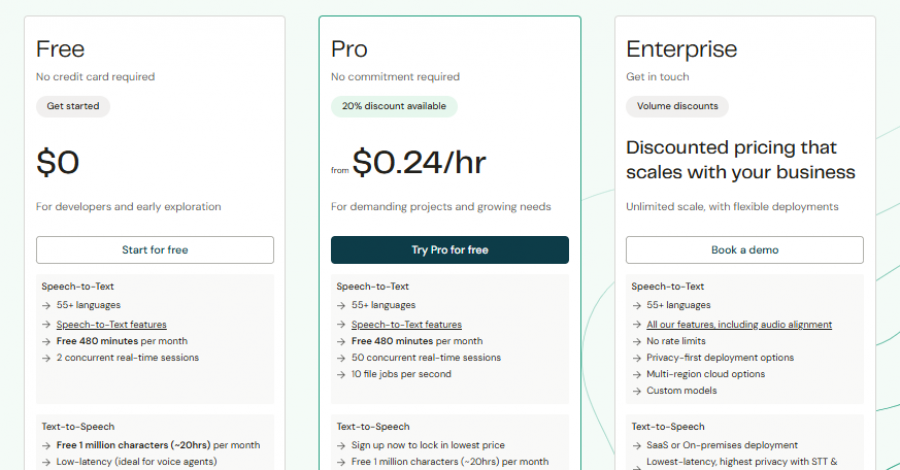
*Check the current pricing on Speechmatics's website.
AI Voice Generator with Ultra-Realistic AI Voices
Why Sonix? Discover the World's Most Advanced AI for Transcription
Modern Technical Computing
Type with your voice in any language
Artificial Intelligence (AI) Assistant, Dictation, LLM & Automation Software
Speechlogger: Automatic transcription, captioning & instant translation