In a major development for the AI audio space, French startup Mistral has unveiled Voxtral, its first family of open-source AI audio models. Designed to rival proprietary systems while offering the flexibility of open-source technology, Voxtral aims to democratize access to high-performance speech recognition and audio understanding models.
With its ability to generate, transcribe, and comprehend speech, Voxtral could be real among many industries have been waiting for.
Mistral’s bold foray into the audio model market provides businesses with a powerful tool for leveraging native semantic understanding and long-form audio context, all without the constraints and high costs of closed-source platforms.
Key Features of Voxtral
1. Multilingual Support
Voxtral comes with a robust multilingual architecture, supporting languages such as English, Spanish, French, Portuguese, Hindi, German, Dutch, and Italian. This makes it a strong candidate for global applications, from multilingual customer service to international media transcription.
2. Long-Form Context Handling
One of the standout features of Voxtral is its 32k token context length. This enables the model to transcribe audio inputs up to 30 minutes for transcription and 40 minutes for comprehension, making it ideal for podcasts, webinars, interviews, and other long-form content that standard models struggle with.
3. Native Semantic Understanding
Unlike traditional transcription models, Voxtral doesn’t just transcribe speech; it also provides semantic understanding. Built on the Mistral Small 3.1 model, Voxtral delivers summarization, question-answering, and actionable insights based on the content of the audio, making it a powerful tool for interactive applications.
4. Open-Source Accessibility
Released under the Apache 2.0 license, Voxtral is fully open-source, meaning developers and businesses can tweak and fine-tune the model to suit their needs. This offers a huge advantage over proprietary systems that restrict customization or integration options.
Model Variants: Flexibility for Different Use Cases
Voxtral comes in multiple configurations, catering to both large enterprises and smaller, more resource-constrained environments:
- Voxtral Small: A 24B parameter model for high-accuracy, production-ready deployments.
- Voxtral Mini: A more resource-efficient 3B parameter model, perfect for edge deployments.
- Voxtral Mini Transcribe: A specialized transcription-only variant, offering cost-effective transcription with higher performance than OpenAI’s Whisper.
This flexibility allows businesses of all sizes to harness the power of AI audio models, regardless of their technical resources.
Competitive Edge: Voxtral vs. Whisper & ElevenLabs
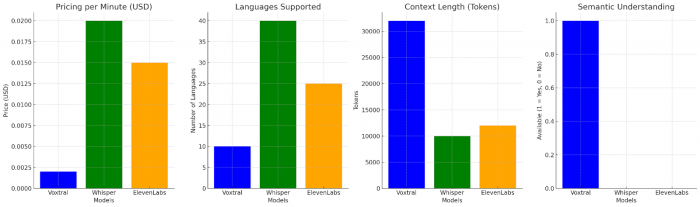
Mistral's Voxtral positions itself as a direct competitor to other audio models like Whisper (by OpenAI) and ElevenLabs Scribe. What sets Voxtral apart?
- Pricing: Mistral's offering is significantly more affordable, with a cost per minute that is lower than Whisper and much cheaper than ElevenLabs.
- Customization: As an open-source model, Voxtral allows complete control over deployment, customization, and integration, which proprietary models like Whisper and ElevenLabs don’t.
- Performance: Early tests show that Voxtral’s long-form handling and semantic understanding outperform other models in real-world transcription and comprehension tasks.
For developers and businesses looking to incorporate speech AI into their systems, Voxtral’s open-source nature and competitive pricing make it an attractive choice.
Developer-Friendly: Easy Deployment & Integration
Voxtral is designed to be as developer-friendly as possible. It is available on Hugging Face and through Mistral’s API, allowing businesses to integrate AI audio capabilities into their platforms with ease. Whether you are deploying the model to handle live audio transcription, post-production audio editing, or even voice-triggered commands, Voxtral fits seamlessly into a wide variety of use cases.
The Future of Open-Source AI Audio Models
As AI becomes more ingrained in our everyday digital interactions, the demand for high-quality, cost-effective audio models continues to rise. Voxtral’s open-source availability could be a milestone in democratizing AI audio technology, allowing businesses of all sizes to harness speech recognition and understanding without the heavy licensing fees and limitations of proprietary models.
Looking forward, Mistral plans to continue refining Voxtral and expanding its capabilities. Expect improvements in speech quality, real-time performance, and integration with other AI technologies. As developers and businesses begin to explore Voxtral’s potential, we can expect to see new and innovative use cases across industries like customer service, media, healthcare, and enterprise automation.
Conclusion: Mistral’s Bold Step into the AI Audio Space
With the release of Voxtral, Mistral has made a bold statement in the open-source AI audio space. By combining powerful features, affordability, and the flexibility of open-source technology, Voxtral is setting the stage for a more inclusive future of AI-driven speech and audio solutions. For businesses, developers, and enthusiasts looking to reimagine the future of speech AI, Mistral’s Voxtral is a significant leap forward.
Post Comment
Be the first to post comment!





