On This Page
- What Is Veo 3?
- What’s the New Image-to-Video Feature?
- First-of-Its-Kind: AI Video with Built-in Audio
- Where and How to Use It
- Adoption So Far: 40 Million+ Videos Created
- Responsible AI: Safety and Red-Teaming
- Technology Behind Veo 3
- Subscription Tiers and Access Limits
- Real-World Use Cases
- Competition: How Veo 3 Compares
- Known Limitations
- What’s Next for Veo?
- Final Take
Google has added a powerful new feature to its Veo 3 video generation model: the ability to turn a single image into a short video—complete with movement and sound. Announced on July 10, 2025, this feature is now available in both Google Flow and the Gemini app for Pro and Ultra subscribers.
This marks a significant step in generative AI’s creative utility, enabling users to go beyond text prompts and animate static photos with motion and audio, all within seconds.
What Is Veo 3?
Veo 3 is Google’s flagship text-to-video AI model. First introduced at Google I/O 2025, it can generate cinematic-quality videos from text, now enhanced to accept images as input.
The model is accessible via:
- Google Flow (a browser-based video creation tool)
- Gemini web and mobile apps (for creative users and casual creators)
- Vertex AI on Google Cloud (for developers and enterprise integration)
What’s the New Image-to-Video Feature?
The new feature allows users to:
- Upload a single image
- Add a text prompt describing motion and sound
- Generate an 8-second video (720p resolution)
- Receive videos with synchronized sound effects, voices, or background music
Users can make up to 3 videos per day, with no rollover of unused credits. Videos are also watermarked using SynthID, both visibly and invisibly, to ensure responsible use and prevent misuse.
First-of-Its-Kind: AI Video with Built-in Audio
Veo 3 stands out from rivals like Runway, Pika, and Sora by generating both visuals and sound in a single workflow.
According to Google, this includes:
- Environmental audio (e.g., birds chirping, city noise)
- Dialogue or voiceover
- Music backgrounds
It’s the first major video model to support native audio synchronization—a major leap for generative content platforms.
Where and How to Use It
Currently Available On:
- Gemini for Web (desktop browser)
- Google Flow (flow.google.com)
Coming Soon To:
- Gemini Android & iOS apps
- Rollout expected within weeks, according to Google’s official blog.
Adoption So Far: 40 Million+ Videos Created
Since Veo 3’s release in May, users have created over 40 million videos, signaling strong demand for AI-driven storytelling tools.
The inclusion of image-to-video further expands its accessibility for:
- Educators and content creators
- Marketers and designers
- Casual users seeking animated memories or social content
Responsible AI: Safety and Red-Teaming
Google emphasizes safety in rollout:
- Every video includes SynthID watermarks (visible + invisible)
- The tool underwent extensive red-teaming to mitigate risks around misinformation, impersonation, or political misuse
- Prompts and results are filtered using Google’s safety classifiers, including for violent or sensitive imagery
Technology Behind Veo 3
Veo 3 leverages:
- Large-scale diffusion for frame-by-frame visual synthesis
- A multi-modal transformer backbone that connects audio, motion, and visual cues
- Temporal consistency algorithms, which ensure smoother motion transitions over frames
- Access via Vertex AI’s Generative AI Studio for custom workflows
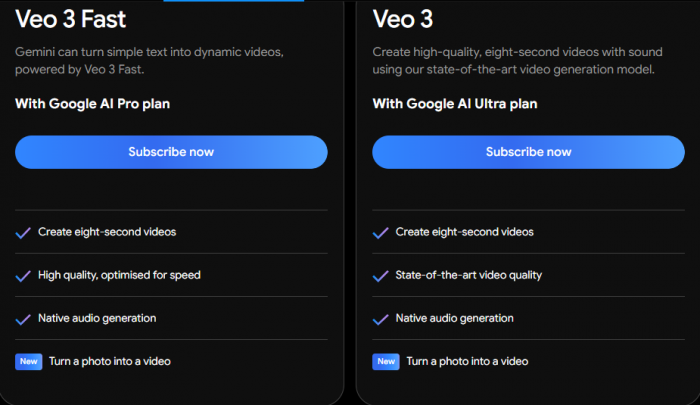
Subscription Tiers and Access Limits
Real-World Use Cases
Marketing & Ads
Brands can animate product shots for dynamic social media campaigns.
Education & Storytelling
Teachers can bring historical photos or book illustrations to life.
Personal Creators
Users can animate travel photos or portraits for sharing on platforms like YouTube Shorts or Instagram Reels.
Competition: How Veo 3 Compares
| Feature | Veo 3 | Runway Gen-3 | Pika Labs | OpenAI Sora (preview) |
| Input Types | Text, Image | Text, Video | Text, Image | Text, Image |
| Audio Generation | Yes (built-in) | No | No | Not yet live |
| Video Length | 8 seconds | Up to 6 seconds | Up to 4 seconds | Variable (internal use) |
| Safety Tools | SynthID + Filters | Blur + Human review | NSFW filters | Not fully disclosed |
Known Limitations
- Lip-sync issues: Voices may not always match facial movements accurately
- Prompt sensitivity: Some results may be inconsistent depending on image quality
- Creative control: Limited tuning options for frame pacing, camera motion, or color style
What’s Next for Veo?
According to the Google Cloud and DeepMind teams:
- Longer videos and higher resolutions (e.g., 1080p+) are in experimental stages
- Multilingual audio prompts support may be added in future Gemini updates
- Expanded image editing and video chaining (linking multiple clips) are under internal testing
Final Take
Google’s latest update to Veo 3—turning still images into audio-synced, realistic video—isn’t just a gimmick. It’s a practical step forward in democratizing animation and storytelling with AI. With safety layers in place and cross-platform rollout underway, Veo 3’s evolution reflects Google’s growing commitment to responsible, useful generative media.
Post Comment
Be the first to post comment!





